These weren’t stolen databases: they were chats shared via public links and, critically, marked as discoverable.
The feature’s idea was to let helpful conversations reach a wider audience, but in practice it exposed thousands of private exchanges.
By August 1, OpenAI disabled discoverability and began coordinating with search engines to remove indexed pages.
Within days, a researcher scraped nearly 100,000 conversations, proving how fast public content can be copied once it’s crawlable.For ongoing context across model releases, safety notes, and policy shifts, browse our Artificial Intelligence tag — we follow the ecosystem as changes land.
Visual timeline of events
July 29, 2025 — First public sightings: shared ChatGPT pages appear in Google Search; privacy concerns start trending.
July 30, 2025 — Media coverage expands; researchers verify thousands of indexed conversations.
August 1, 2025 — OpenAI removes the discoverability toggle globally and initiates de-indexing with search engines.
August 6, 2025 — Independent dataset shows ~100,000 exposed chats, illustrating the scale of the ChatGPT leak.
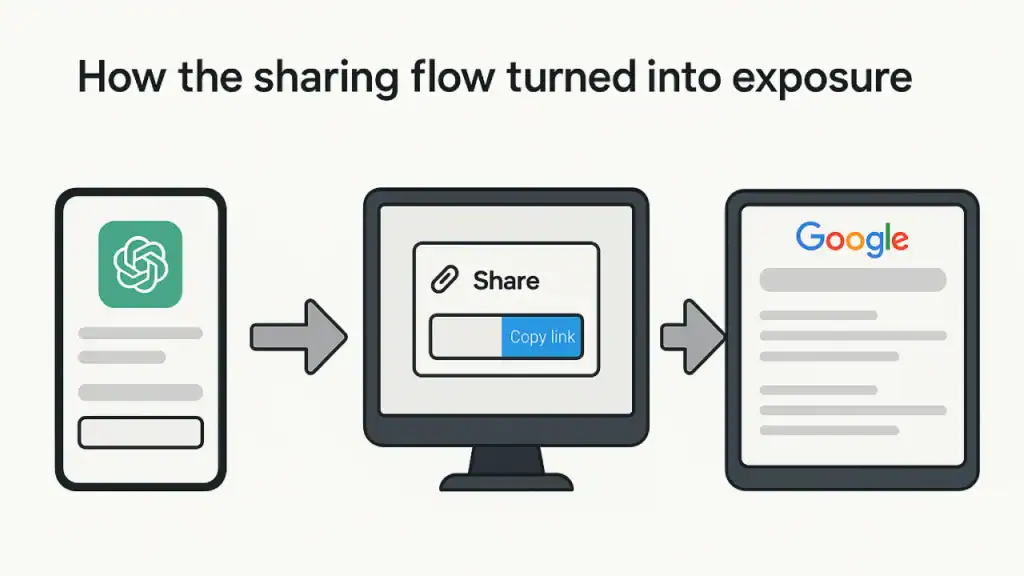
How the sharing flow turned into exposure
What leaked — and what didn’t
Precision matters. The ChatGPT leak did not involve breaking into private accounts or compromising OpenAI’s core infrastructure.
The pages that surfaced came from the standard sharing flow, where users could create a public URL and, optionally, allow search engines to discover it.
Many people appear to have misread this control and unintentionally published private content.
The exposed material ranged from everyday troubleshooting to deeply personal topics: health worries, relationship struggles, career and finance questions.
For businesses, the blast radius was bigger: prototype notes, contract drafts, vendor evaluations, and roadmap fragments.
Once a page is crawlable, a simple site:chatgpt.com/share query can pull up fragments that were never meant for broad discovery.
☕ Enjoying the article so far?
If yes, please consider supporting us — we create this for you. Thank you! 💛
Quick & easy — no registration needed
Why the dates matter
The timing shows how quickly a design choice can become a story. Between July 29 and August 1, the situation shifted from scattered reports to a company-level rollback.
By August 6, independent aggregation quantified the scope. The arc is classic: visibility, validation, volume — and the public framing of a ChatGPT leak.
UX lesson: a small control, a big consent gap
Users equate “share” with limited distribution. On the open web, a shareable link is effectively a published page unless explicitly blocked.
That’s the consent gap at the heart of this incident: a compact checkbox with consequences far wider than most people expect.
When the content is an LLM conversation — a space where people think out loud — the stakes are inherently higher.
Scale: from thousands to six figures
Early tallies spoke of a few thousand pages. The subsequent dataset of ~100,000 conversations made it clear: once something is public, it is
copy-by-default. Indexes, caches, and mirrors extend the lifetime of a page well beyond the original link — a central reason the ChatGPT leak resonated.
Google indexing, caching — and how noindex helps
Search engines honor signals. A page that includes <meta name="robots" content="noindex"> asks crawlers not to include it in results.
That doesn’t encrypt the content or block access via a direct URL, but it removes the discovery vector that turned this incident into news.
If discoverability had shipped with a default noindex (lifted by an explicit confirmation), the ChatGPT leak would have been far smaller.
Even with de-indexing, cached snapshots and third-party mirrors may linger temporarily. Removing the original, then filing “outdated content” requests with major search engines,
shortens that tail — but time and persistence vary.
Why this felt different from routine “oversharing”
The web is full of misconfigurations — open buckets, public trackers, exposed tickets. This incident cut deeper because it involved intimate LLM dialogue.
Seeing your own words in a search snippet is uniquely jarring: identity breadcrumbs, medical hints, relationship stress, amateur legalese, workplace politics.
For teams, the risk folds into competitive intelligence: a single toggle can surface strategy that never should leave the room.
Business implications: contracts, retention, and accountability
Enterprises adopting LLMs need hard edges: contractual guarantees on data handling and deletion, clear retention settings, and audited export/sharing controls.
A policy that treats “share” as “publish” avoids ambiguity. Role-based restrictions, domain-level link blockers, and default noindex are practical safeguards.
The ChatGPT leak is a governance case study more than a network story: the weak link was the decision layer presented to end users.
If your org is evaluating AI tooling, start with a privacy threat model. What can leave, via which routes, with which signals to crawlers, and how is revocation enforced?
Answers to those questions turn into both product requirements and vendor clauses.
Practical mitigation: do this now
- Audit old share links; delete those you don’t want online. Then submit the URLs to “outdated content” tools.
- Segregate secrets: never paste credentials, unreleased financials, or HR details into chats without enterprise controls.
- Enforce defaults: private by default, explicit “publish” confirmation, and
noindexunless the user consciously lifts it. - Govern exports and link sharing with policy + technical controls; review logs for accidental exposure during the visibility window.
We track similar incidents and fixes in our Security Watch section — follow along as platforms adjust their safeguards.
FAQ: quick answers
Was my private chat exposed? If you never created a public share link, it wasn’t eligible for indexing. The ChatGPT leak involved pages that users shared and marked discoverable.
Can I remove traces from search? Delete the page, then request removal through search engines’ tools. Caches and mirrors may take time to vanish.
Is this just user error? It’s a design-meets-behavior problem: people expect “share” to mean controlled distribution, not publishing to the public web.
What should businesses require from vendors? Data-deletion SLAs, clear retention controls, link-sharing governance, default noindex, and auditable logs.
Bottom line
The ChatGPT leak wasn’t a server breach — it was a discoverability design that blurred sharing and publishing.
OpenAI’s rollback limited further harm, but the lesson is durable: privacy-first defaults and unmistakable wording are security controls, not UI polish.
Until platforms and policies reflect that, we’ll keep seeing versions of the same story.
For deeper context, analysis, and follow-ups across models and policies, keep an eye on our AI coverage and the continually updated Security Watch.
Did you enjoy the article?
If yes, please consider supporting us — we create this for you. Thank you! 💛
Quick & easy — no registration needed
Exclusive content & community perks
Follow us on social media:

